This research paper presents a rigorous benchmark comparing generalist large language models with specialized encoder-based models for the task of Arabic sentiment analysis on noisy, real-world data.
Models Evaluated:
- Llama-3 (Generalist LLM)
- Qwen-2.5 (Generalist LLM)
- CAMeLBERT (Specialized Arabic Encoder — Baseline)
Dataset:
- 3,822 samples of Arabic company reviews
- Noisy, colloquial Arabic from real-world sources
- Binary sentiment classification (positive/negative)
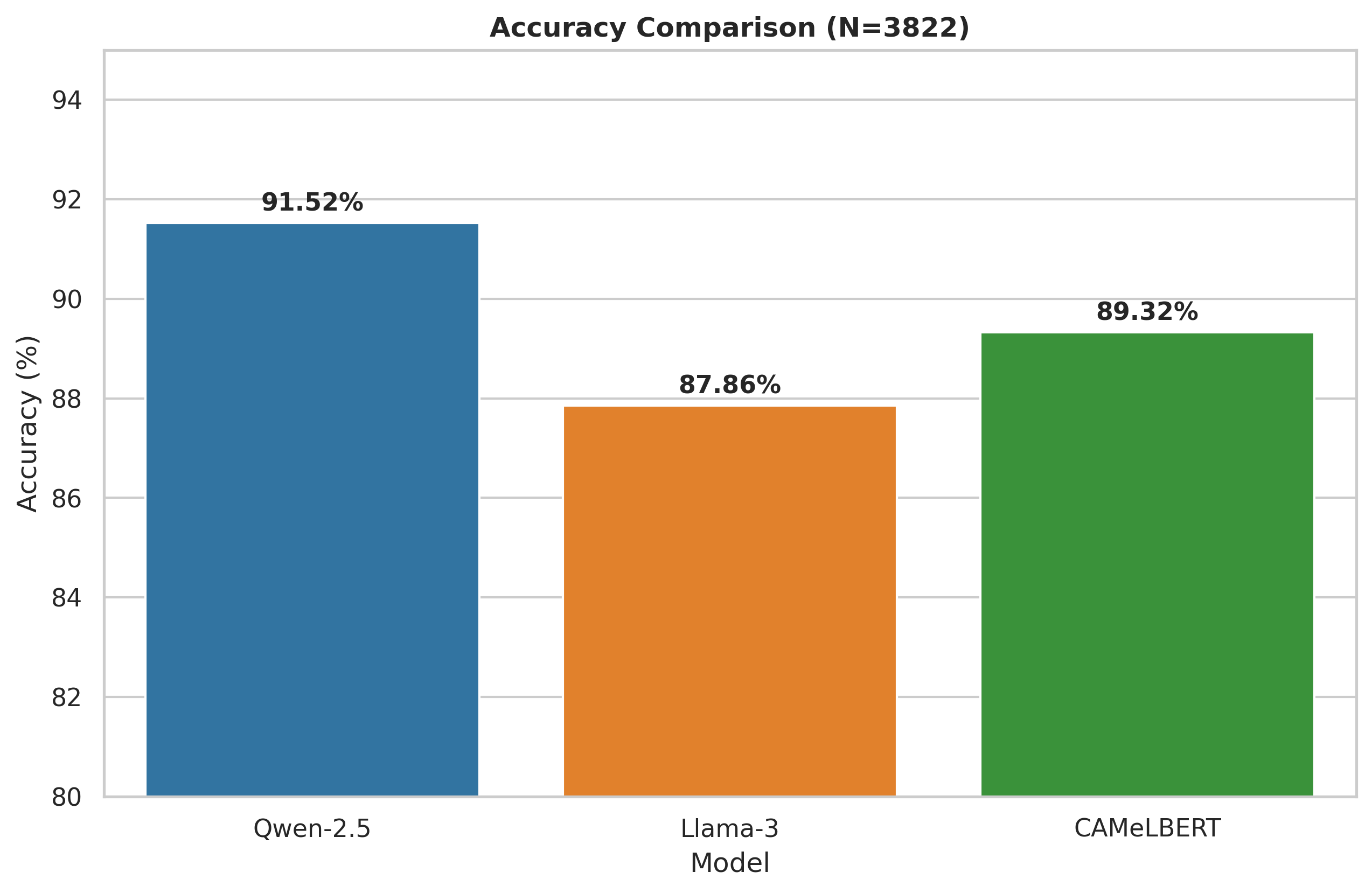
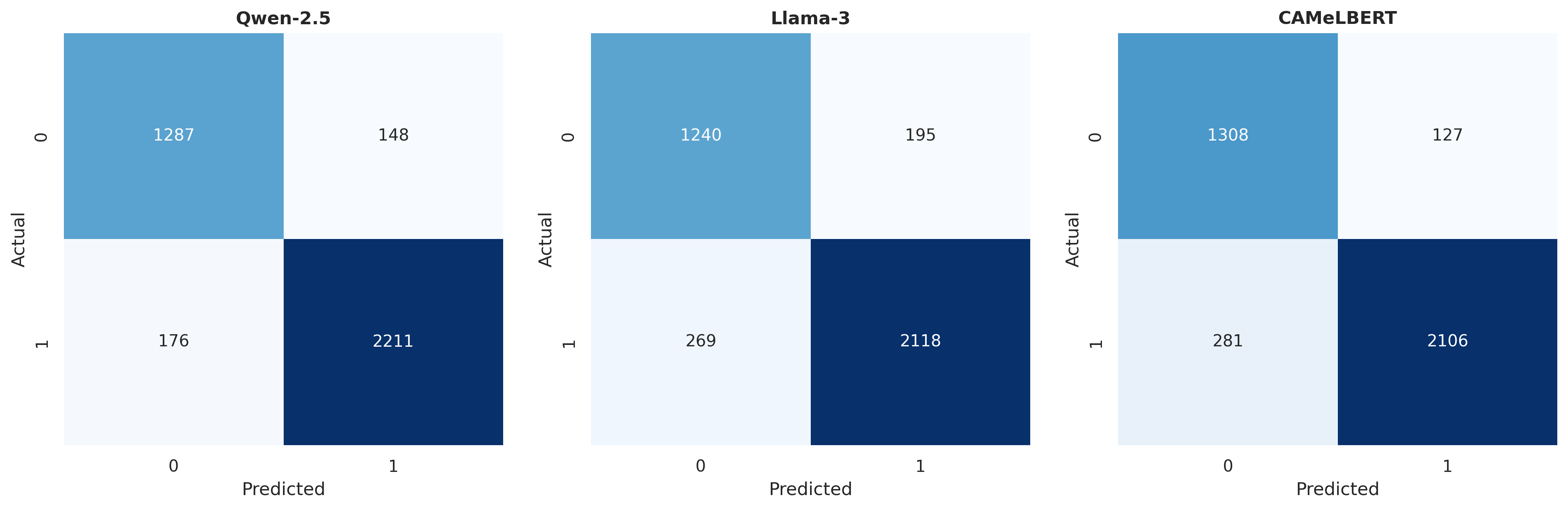
Key Results
| Model | Accuracy | F1-Score | Avg Latency |
|------------|----------|----------|-------------|
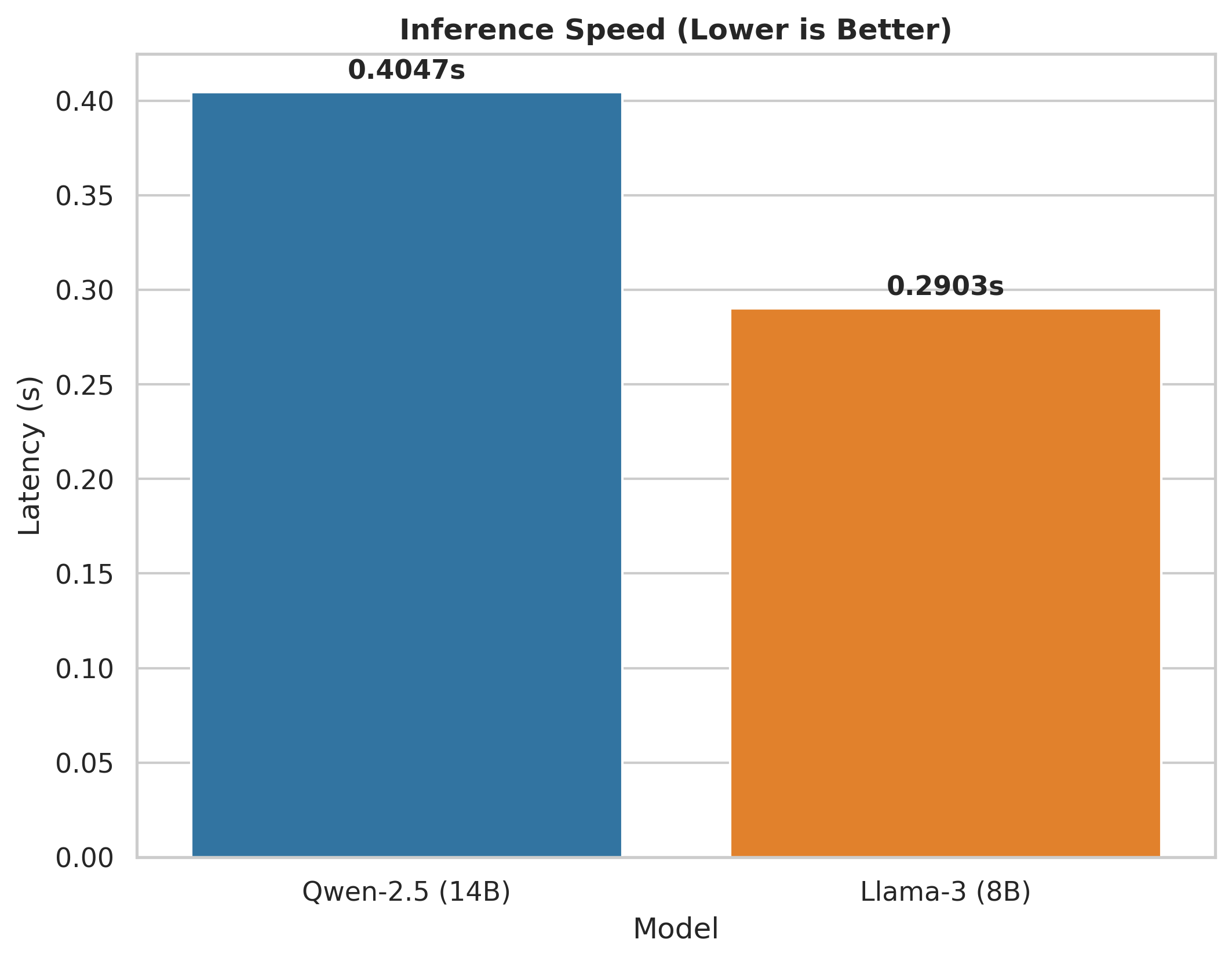
| Qwen-2.5 | 91.52% | 91.54% | 0.405s |
| CAMeLBERT | 89.32% | 89.42% | N/A (base) |
| Llama-3 | 87.86% | 87.92% | 0.290s |
Findings:
- Qwen-2.5 achieves the highest accuracy (91.5%) but is 28.3% slower than Llama-3
- Llama-3 offers the best accuracy-speed trade-off for production systems
- Statistical significance confirmed (McNemar test, p < 0.00001)
- Specialized encoders remain competitive for resource-constrained deployments
Practical Recommendation: For Arabic sentiment pipelines, Llama-3 provides the optimal balance of speed and accuracy.
تقدم هذه الورقة البحثية قياساً دقيقاً مقارناً بين نماذج اللغة الكبيرة العامة والنماذج المتخصصة لمهمة تحليل مشاعر اللغة العربية على بيانات حقيقية مضوضاة.
النماذج المقيَّمة:
- Llama-3 (نموذج لغوي كبير عام)
- Qwen-2.5 (نموذج لغوي كبير عام)
- CAMeLBERT (مشفِّر عربي متخصص — الخط الأساسي)
مجموعة البيانات:
- 3,822 عينة من مراجعات الشركات العربية
- عربية عامية مضوضاة من مصادر حقيقية
- تصنيف ثنائي للمشاعر (إيجابي / سلبي)
النتائج الرئيسية:
- Qwen-2.5 يحقق أعلى دقة (91.5%) لكنه أبطأ بنسبة 28.3% من Llama-3
- Llama-3 يوفر أفضل توازن بين الدقة والسرعة لأنظمة الإنتاج
- دلالة إحصائية مؤكدة (اختبار McNemar، p < 0.00001)
- المشفِّرات المتخصصة تظل تنافسية للبيئات محدودة الموارد
التوصية العملية: لخطوط أنابيب تحليل المشاعر العربية، يوفر Llama-3 التوازن الأمثل بين السرعة والدقة.
Technologies Used
🖼️ Screenshots & Figures